在Java8 stream部分和上一篇博客都有用到ForkJoinPool,这个是ForkJoin框架创建的线程池。所以开始了解下这个是ForkJoin框架是什么。
线程池
先学习下线程池的知识。
概念
线程池是一种预先创建多个线程的机制。预先启动若干个线程,放入池子中,让线程处于睡眠状态,这样不会耗费CPU资源。当一个请求来到的时候,从线程池中唤醒一个睡眠的线程来处理这个请求,请求完成后,再让线程回到睡眠状态。
好处
- 避免线程的反复创建,销毁产生的开销。
- 请求任务来到的时候,直接从线程池中取出线程来用,提高响应速度,无需等待新线程的创建。
- 线程池可以有效管理线程的数量,避免无节制的创建线程。
流程
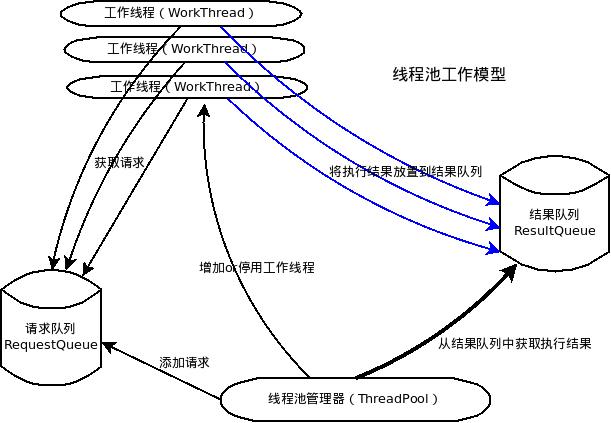
一个简易的线程池的流程如下图:
ThreadPoolExecutor
JDK5提供了线程池功能,下面是这个类的主要实例域。
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
但是创建线程池还是推荐用上一篇提到的Executors的静态方法。
ThreadPoolExecutor线程池流程
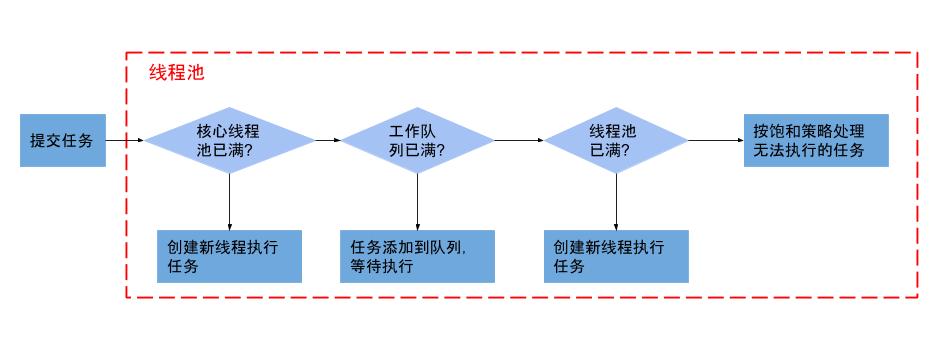
- 新来一个任务时,先看当前线程数,如果小于corePoolSize, 则直接创建新线程。 否则进步下一步。
- 查看任务是否已满,如果没满,放入任务队列,否则进入下一步。
- 查看线程池是否已满,如果没满,创建新线程。否则利用饱和策略。
ForkJoin框架
概念
ForkJoin是JDk7加进来的,一个用于并行处理任务的框架。
这个框架采用分治法的思想,Fork意为将大任务递归的分割成可以处理的小任务,Join意为将小任务的结果再结合起来。从而得到大任务的最终结果。
框架思想
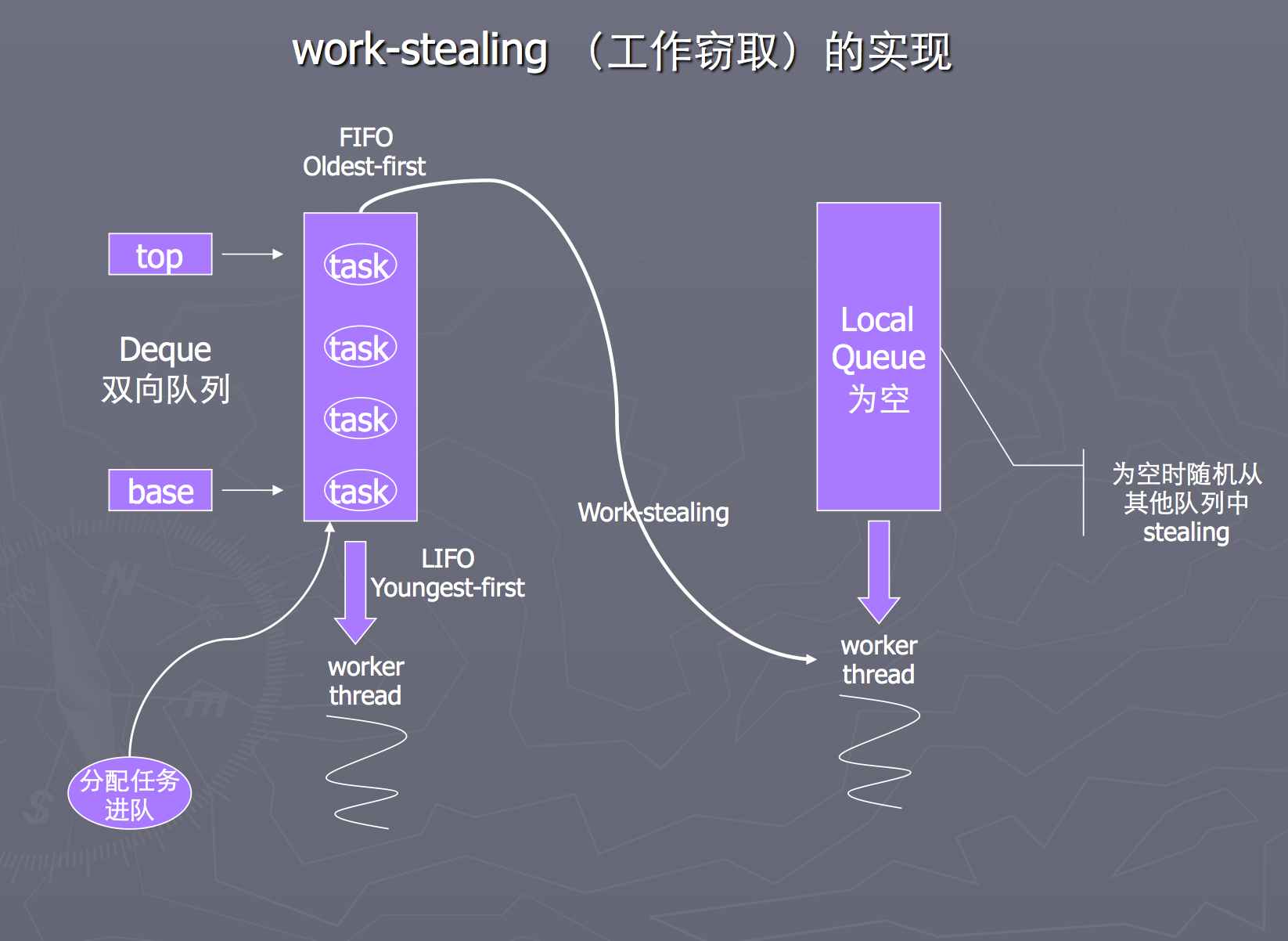
ForkJoin的核心思想是work-stealing(工作窃取)。
- 当一个比较大的任务进来的时候,我们可以把大任务分割成互不依赖的子任务,并把这些子任务放到不同的
双端队列中,然后为每个队列分配一个线程来处理子任务。 - 自己队列的任务再分割的时候,会从队列头部放到自己的队列中。处理任务的时候,通过LIFO(后入先出)的顺序,从队列头部弹出任务来处理。
- 有的队列先把自己的任务做完了,就可以从其他队列去窃取任务,通过FIFO(先入先出)的顺序,从要去窃取的队列尾部拿任务。这样既减少了竞争,也尽量的窃取到了相对比较大的任务。
ForkJoin使用
这里贴一个例子,利用ForkJoin框架计算数组和的方法。
给定一个int数组,如果数组长度大于5000,就将这个任务分割成2个任务,分别计算数组的左半部分和右半部分,如果分割后的数组长度还大于5000,就继续分割,直到小于5000。 然后来计算子任务的值,并最后加起来。
1 | import java.util.concurrent.ForkJoinPool; |
ForkJoinPool
ForkJoinPool提供静态方法commonPool来创建ForkJoinPool的线程池。
这个线程池的数量依赖于CPU的核数,在我的机器上,它为3。1
2
3System.out.println(ForkJoinPool.commonPool().getParallelism());
//3
可以通过修改JVM参数修改默认的线程数量。1
-Djava.util.concurrent.ForkJoinPool.common.parallelism=5