Zuul
简介
之前的微服务都是内部之间相互调用,但是如果让外部来调用我们的微服务,我们需要服务网关来作为统一的入口。
- 通过提供统一的Endpoint入口,来降低外部客户端的调用复杂度,外部客户端只需要把它当成一个服务即可,不需要关心内部众多的微服务。
- 将和业务逻辑无关的服务剥离出来,比如认证鉴权,限流,审计等等。
- 通过网关,可以容易的实现蓝绿部署,金丝雀部署等。
基本用法
在应用上添加注解@EnableZuulProxy, 并将其注册到Eureka上,1
2
3
4
5
6
7@SpringCloudApplication
@EnableZuulProxy
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
由于整合了Eureka,网关默认会添加一些路由,它会去注册中心获取服务,自动的加上对应的路由。
比如说注册中心有个hello-service服务,网关会自动将/hello-service/**的转发给hello-service服务。
过滤器
Filter用来对通过网关的请求进行过滤,它有4个生命周期,pre, route, post, error, 如下图所示: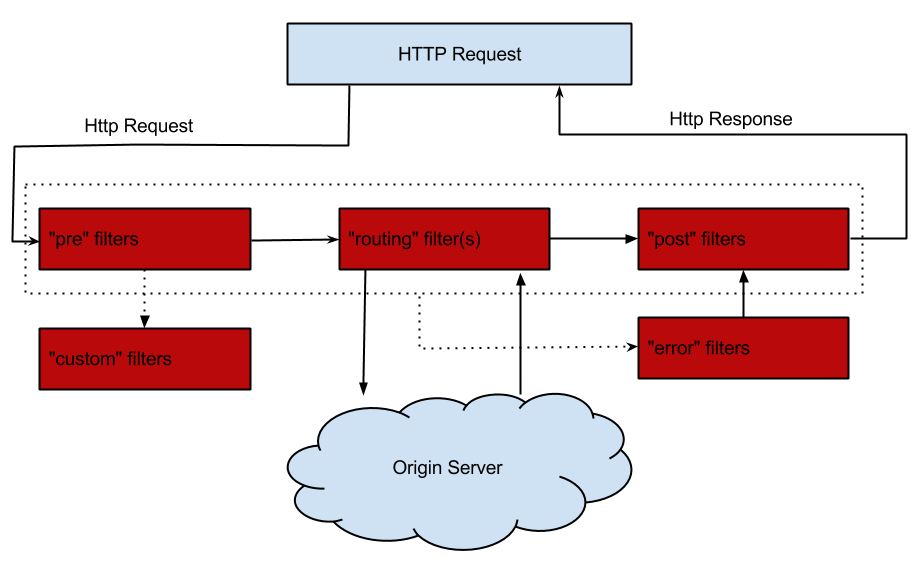
- PRE: 这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
- ROUTING:这种过滤器将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用Apache HttpClient或Netfilx Ribbon请求微服务。
- POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
- ERROR:在其他阶段发生错误时执行该过滤器。 除了默认的过滤器类型,Zuul还允许我们创建自定义的过滤器类型。例如,我们可以定制一种STATIC类型的过滤器,直接在Zuul中生成响应,而不将请求转发到后端的微服务。
通过继承ZuulFilter可以自定义Filter。
Sleuth & Zipkin
在微服务中,服务之间的调用关系复杂,通常来自客户端的请求,在后端会经过多个不同的微服务,形成一条分布式的链路。那么Sleuth和Zipkin就是用来进行分布式链路的跟踪,可以很容易的发现一条链路上到底哪里出了问题,或者哪里耗时比较长等等。Sleuth用于收集分布式的链路信息,将其通过http或mq发送给Zipkin展示出来。
基本用法
搭建Zipkin server。 单独起个Zipkin服务来收集信息。
引入依赖
1
2compile('io.zipkin.java:zipkin-server')
compile('io.zipkin.java:zipkin-autoconfigure-ui')启动类添加
@EnableZipkinServer注解1
2
3
4
5
6
7@SpringBootApplication
@EnableZipkinServer
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}配置如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15spring:
application:
name: zipkin-server
server:
port: 9411
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka
management:
security:
enabled: false在需要跟踪的服务中引入依赖,就会默认将链路信息发送给9411端口的Zipkin server
1
2compile('org.springframework.cloud:spring-cloud-starter-sleuth')
compile('org.springframework.cloud:spring-cloud-starter-zipkin')
然后在打出来的日志中就会发现多了如下信息。[bff,148ab1e00b07d6b2,6faee1e38537d312,false]
bff表示应用的名称
148ab1e00b07d6b2表示TraceID,同一条链路会使用同一个TraceID,利用它将分布式的信息链接起来。
6faee1e38537d312表示SpanID,它表示一个基本的工作单元,比如说发送一个HTTP请求,
false表示是否发送给zipkin。为了性能的原因,默认采样率为10%
收集机制
Sleuth参考Dapper’s的论文实现。
- Span: 基本的工作单元,比如发送一个RPC请求是一个新的Span。Span可以开始和停止,这样来跟踪消耗的时间,一旦开始了一个Span,之后就必须停止它。
- Trace: 一系列的Span组成的树形结构。
- Annotation: 用来记录时间的发生,比如cs(Client Sent), sr(Server Received), ss(Server sent), cr(Client Received)
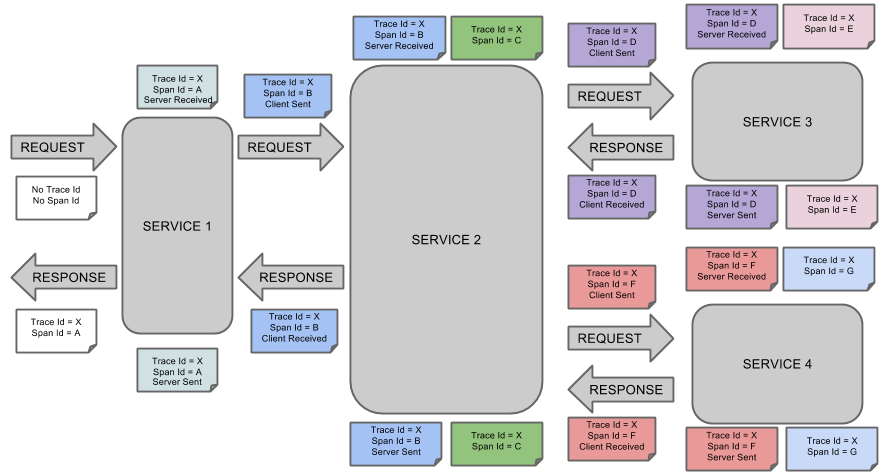
我创建了4个服务模拟了上面的4个service。最终在Zipkin上得到下图: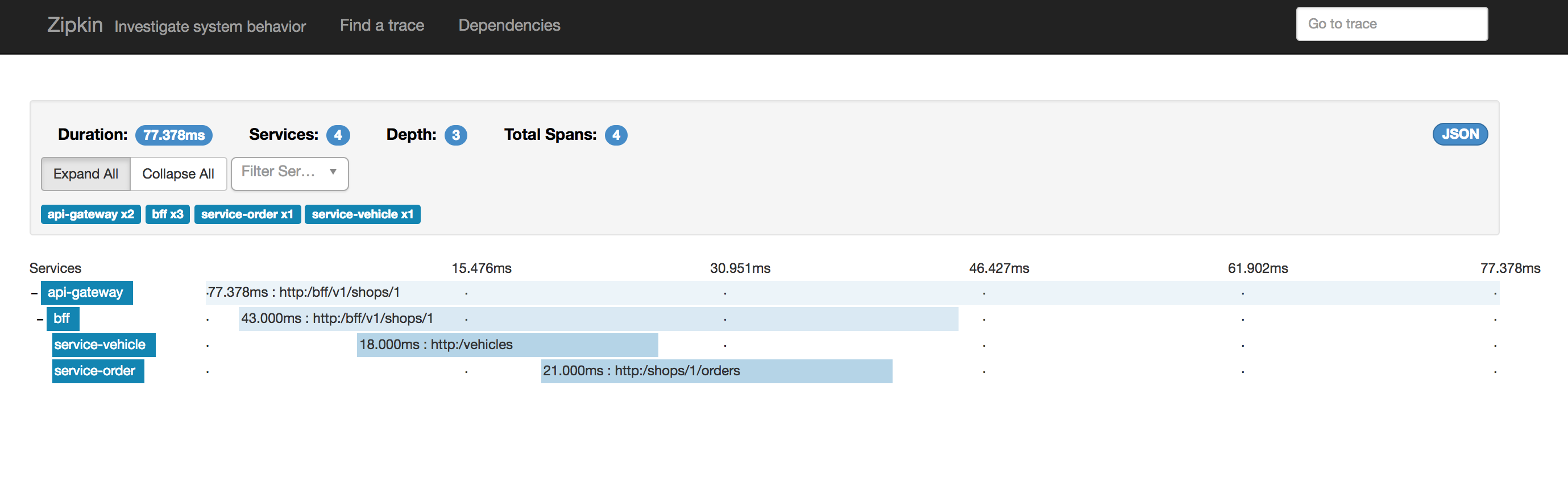
可以看到在ExpandAll下面一列列出了对应的Span数量,总过是7个,对应了官网的图。但是Total Spans却是4个,这是因为zipkin进行的Span的合并。一个Span和客户端调用api-gateway有关,剩下3个和内部3次RPC调用有关。