Spring Cloud Hystrix
在微服务的环境中,往往由多个独立部署的服务组成,服务间通过远程调用来相互交互。
通常一个服务会被多个服务依赖,一个服务也会依赖多个其他的服务。但是如果依赖的服务发生延迟或者故障,导致调用方也发生延迟,随着请求的增加,线程无法释放,导致调用方自身的服务也奔溃。进而甚至导致整个系统雪崩。
因此出现了Hystrix这种服务隔离方案,Spring Cloud Hystrix是基于Netflix的开源Hystrix框架实现的,它提供了服务降级,服务熔断,线程隔离,监控等服务。
基本用法
添加@EnableCircuitBreaker注解到启动类上,或者直接用@SpringCloudApplication注解。
1 | class ConsumerService { |
通过在方法上添加@HystrixCommand注解,然后该方法会被HystrixCommandAspect切面拦截,生成HystrixInvokable来调用。注解上参数的用法:
- fallbackMethod 定义服务降级方法,降级方法的方法签名需要一样,并在同一个类中。
- groupKey 定义hystrix操作的组名,之后可以在配置文件中定制化该group的设置。
- commandKey 定义hystrix操作的命令名,之后可以在配置文件中定制化该command的设置。
定制化配置例子1
2
3
4
5
6
7
8#定义commandKey为helloKey的过期时间为3s
hystrix.command.helloKey.execution.isolation.thread.timeoutInMilliseconds=3000
#定义所有的默认过期时间为5s,不再是默认是1s。优先级小于上面配置
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=5000
#定义threadPoolKey为helloGroup的线程池大小为15
hystrix.threadpool.helloGroup.coreSize=15
#定义所有的线程池大小为为5,不再是默认是10。优先级小于上面配置
hystrix.threadpool.default.coreSize=5
当hello-service挂掉了,或者延迟时间超过了Hystrix的Timeout,Hystrix便会进行降级处理,调用fallback方法返回。这样就起到了对自己服务的保护机制。
依赖隔离
通过Hystrix包装的请求: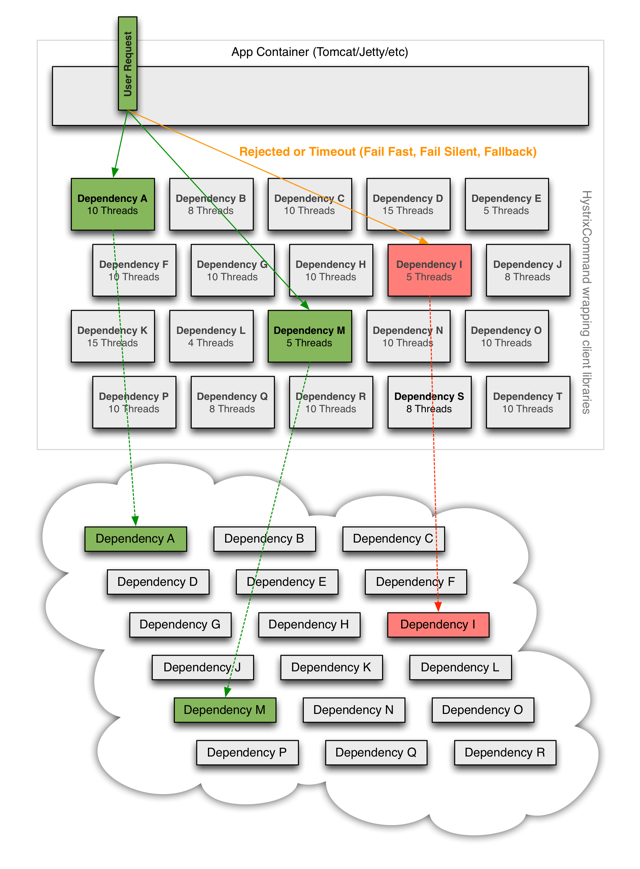
- hystrix通过线程池或信号量来实现服务的依赖隔离,如果选择使用线程池(默认),会为每个command创建一个单独的线程池。
- 当某个command的依赖服务出现问题,也只会让它所属的线程池被影响,不会影响其他服务。
- 当线程池被占满后,之后的command会拒绝服务,而不会等待可用线程。
- 熔断器机制,依赖服务失效达到一定条件,会切断该服务。
除了使用线程池来进行隔离,还可以使用信号量来控制访问依赖服务的并发量。
使用线程池还是信号量取决于依赖服务的类型,如果是需要通过网络访问的,比如第三方API,就需要使用线程池,因为信号量不支持设置超时和实现异步访问。
信号量适用于无网络的高并发请求,因为对于无网络的请求,线程池的开销反而得不偿失。
熔断器
虽然Hystrix已经提供了服务降级功能,但是如果依赖服务挂掉了的话,还是需要等待到超时时间再服务降级,还是可能会产生线程堆积,所以就有了熔断器。
当熔断器触发的时候,便会直接切断该依赖服务,不会等到超时,而是直接调用降级服务。
开启熔断器的条件取决于3个配置:
metrics.rollingStats.timeInMilliseconds滑动时间窗口, 默认为10秒, Hystrix会在这个时间窗口内统计请求失败数是失败率。circuitBreaker.requestVolumeThreshold一个滑动窗口内,触发熔断的最少请求量,默认为20。意味着如果在一个滑动时间窗口内有19个请求,即使19个请求全部失败了,也不会触发熔断。circuitBreaker.errorThresholdPercentage, 触发熔断的失败率,默认为50%, 在滑动时间窗口内,请求数量达到20,其中超过10个失败了,便会触发熔断。
当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,
在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器关闭,主逻辑恢复,
如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。