编译器 vs 解释器
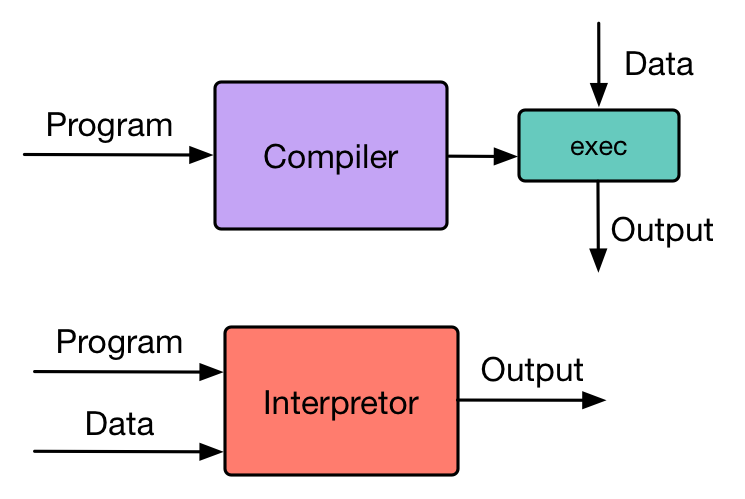
编译器: 输入源代码,输出AST(抽象语法树)或者目标代码(通常是更低级的语言)。比如对Java来说,Java的编译器就是输出字节码(指令序列)。
解释器: 输入源代码,输出执行的结果。 但是解释器也不是平白无故就能解释源代码。 针对解释器的实现,很多解释器内部也是由编译器+虚拟机的方式实现的,比如Python,虽然Python被叫做编译型语言,但实际上是有编译+解释步骤的。
编译器
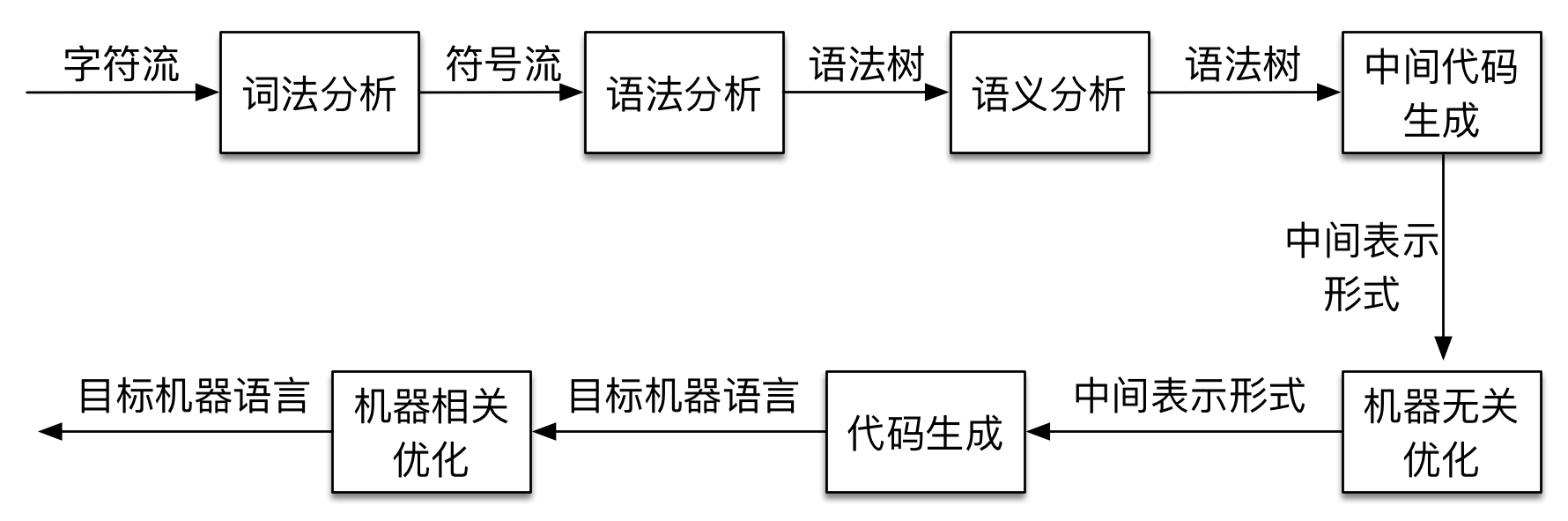
词法分析
概念
词法分析器(Lexer)的作用就是完成源代码->Token流的转换。Token是指词法单元,将源代码拆分成一个个最小的单元,并且在这过程中,需要识别出Token的类型。1
2
3
4public class Token {
private TokenType tokenType;
private Object object;
}
比如说输入下面的代码:1
int num = 1 + 2;
转换成Token Stream如下:
| 类型 | 值 |
|---|---|
| 关键字 | int |
| 标识符 | num |
| 赋值操作符 | = |
| 数字 | 1 |
| 加法操作符 | + |
| 数组 | 2 |
| 结束符号 | ; |
int num = 1 + 2; -> int num = 1 + 2 ;
实现
目前主流的实现还是通过状态机。状态机分为DFA(确定的有限状态机)和NFA(不确定的无穷状态机)。
DFA是指状态A通过事件B只能转换到状态C。
但NFA的状态A通过事件B可以转换到状态C和状态D。
换句话说,同样的状态,通过同样的事件,DFA只能到另外一种状态,但是NFA可以到另外多种状态。
这是一个状态机的例子: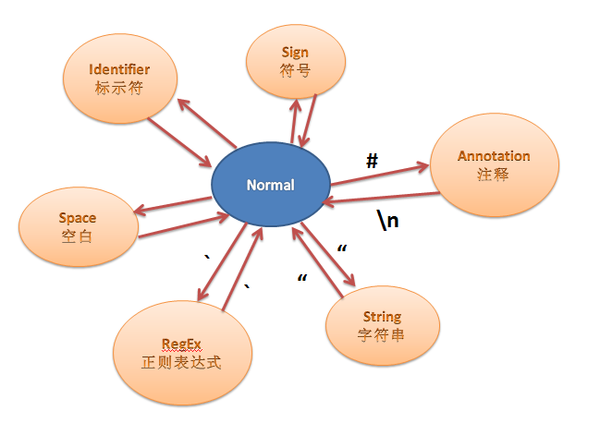
从初始状态,检测下一个字符是什么,如果是",则切换到String状态,这时候期待读入一个字符串,然后在String状态的时候,若检测到下一个字符又是",则回到初始状态。
语法分析
概念
语法分析(Parser)的作用是将上一步生成的Token Stream转换成AST(抽象语法树)。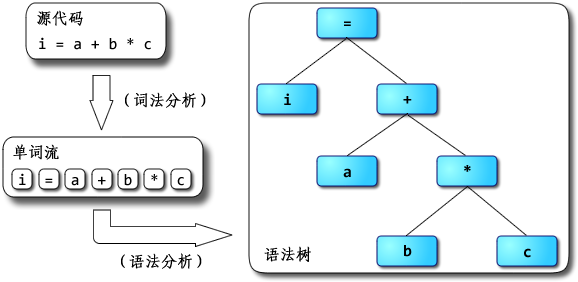
实现
文法
首先介绍一下文法,构成文法的东西叫产生式,比如下面就是1
2
3E → id
E → E + E
E → ( E )
→左边叫非终结符,→右边表示非终结符可以产生的东西,像id,(,),+这种无法继续推导的东西叫终结符。产生式经过推导,可以产生由终结符组成的表达式,比如推表达式(a+b)+c.1
E => E + E => (E) + E => (E + E) + E => (a + E) + E => (a + b) + E => (a + b) + c
这种每次都从最左边的非终结符开始推导的方式叫最左推导,最右推导就是从最右边的非终结符开始推导。
自顶向下和自底向上
语法分析主要分为自顶向下和自底向上的实现方式。
自顶向下就是从文法的开始符号出发,按最左推导的方式推出输入串。常见的方式由递归下降,LL(1),LL(k).
自底向上是从输入串开始,反复查找当前句型的句柄,使用规则,规约成非终结符,最终规约到文法的开始符号。
目前主流的实现方式还是自顶向下。
递归下降
递归下降的思路是将每个非终结符,定义一个程序来完成该非终结符语法的分析和定义。举个简单的例子,比如下面的文法。1
2E → id
E → (E)
id表示任意字母。对上面的文法,E这个非终结符后面可以有2种情况,要么是字母,要么是(。
那当我们输入串为(a)的时候,检测到第一个字符为(,那么用E → (E)来解析。然后(后面,我会期待输入一个非终结符E,而我们实际得到的是a,所以这时用E → id来解析。所以解析过程就是:1
E → (E) → (id) → (a)
而对于LL(1)和LL(k), 第一个L是指从左到右扫描输入串,第二个L是指最左推导。而(1)表示需要向前看多少符号。因为有时候,只根据一个输入字符是无法判断应该用哪种产生式来推导的,需要再往后看1个或n个符号。(k)就是只最多往后看多少个字符。
简单的表达式Parser
学习着写的简单的四则运算的Parser。
大致过程是用Lexer将输入串转换成Token流,然后用Parser将Token流解析成抽象语法树,然后用asm库来生成字节码。
Github地址