protobuf是Google开发的一种数据描述语言,能够将结构化的数据序列化,可用于数据存储,通信协议等方面。类似于XML,Json,Thrift。
用法
我们需要用protobuf提供的语法来写proto协议文件,然后用protoc编译器来编译成想要的语言。
demo.proto
1 | syntax = "proto3"; |
然后用protoc编译器将其编译成Java类。1
protoc -I=./ --java_out=./ demo.proto
生成的Java类
编译后生成的Java类主要由三部分组成。
对每个message, 有个相应的Builder接口, 其中包括获取这个messsage的field的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13public interface PersonOrBuilder extends com.google.protobuf.MessageOrBuilder {
int getId();
java.lang.String getName();
com.google.protobuf.ByteString getNameBytes();
java.util.List<java.lang.String> getEmailList();
java.lang.String getEmail(int index);
java.util.Map<java.lang.String, java.lang.String> getAddresses();
}message对应的Java类
1
2
3
4
5
6
7
8
9
10
11
12public static final class Person extends com.google.protobuf.GeneratedMessageV3 implements PersonOrBuilder {
//自带Builder设计模式
public static final class Builder {
}
//序列化到输出流
public void writeTo(final OutputStream output) {}
//序列化成字节数组
public byte[] toByteArray() {}
//从字节数组反序列化
public static com.demo.Demo.Person parseFrom(byte[] date) {}
public static com.demo.Demo.Person parseFrom(InputStream input) {}Descriptor实例域,用于描述message协议文件, 可以通过Descriptor来获得message的信息。
1
2
3
4
5
6
7private static final com.google.protobuf.Descriptors.Descriptor internal_static_Person_descriptor;
private static final com.google.protobuf.Descriptors.Descriptor internal_static_Person_AddressesEntry_descriptor;
private static final com.google.protobuf.Descriptors.Descriptor internal_static_Person_PhoneNumber_descriptor;
private static com.google.protobuf.Descriptors.FileDescriptor descriptor;
使用
1 | Demo.Person person = Demo.Person.newBuilder() |
多message处理
从上面的例子可以看到,在反序列化字节数组的时候,需要知道它是什么类型的, 那当我们接收到字节数组的时候,怎么知道它是什么类型呢。
oneof
oneof是自带的功能,放在oneof里面的message,只能有一个被赋值。下面的例子里,我们定义个顶层message,将2个message放到oneof里面,这样每次序列化及反序列化的时候,都可以用topMessage这个类,它提供了一个方法,可以知道oneof里面的哪个message被赋值了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16message Person {
int32 id = 2;
string name = 1;
string email = 3;
}
message Address {
string address = 1;
}
message topMessage {
oneof innerMessage {
Person person = 1;
Address address = 2;
}
}
自定义通信协议
这个是陈皓定义的协议,简单来说,当我们将message序列化成字节数组后,在它前面加几个字节来表示这个消息的类型。当反序列化的时候,拿到表示类型的字节,就知道怎么反序列化了。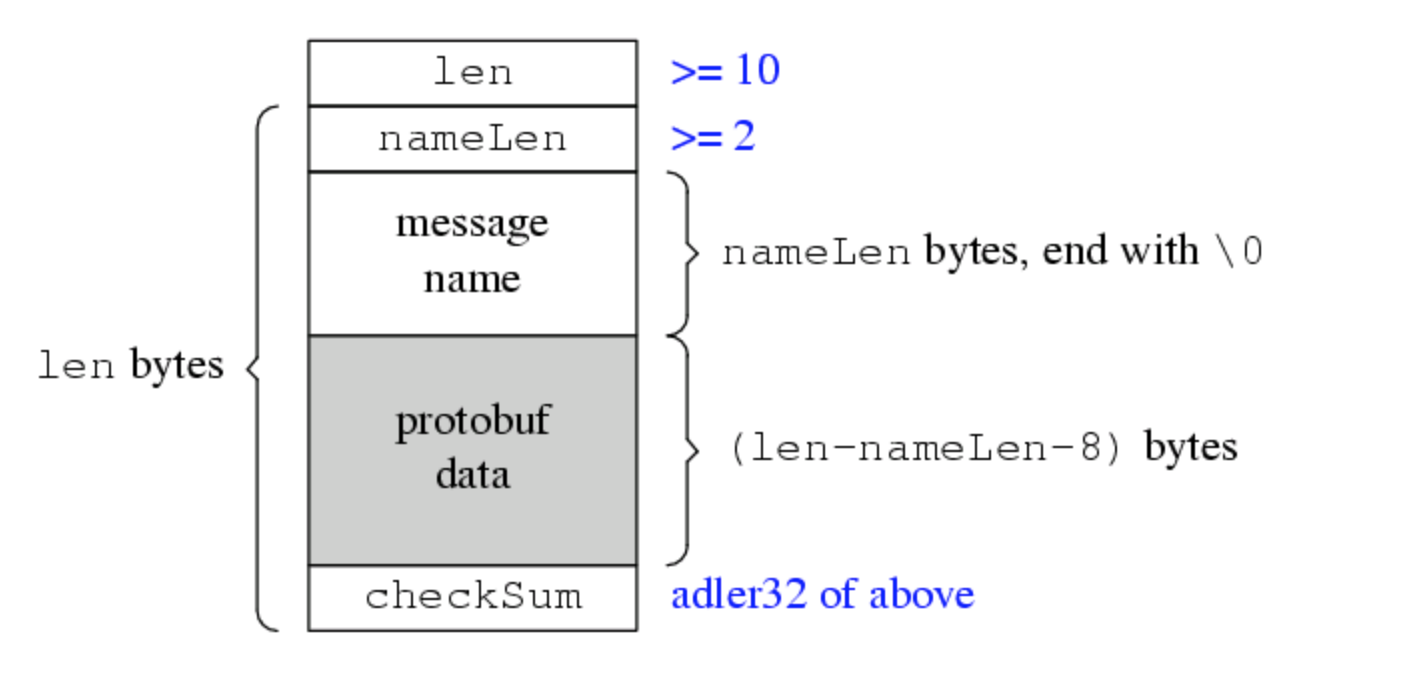
序列化及反序列化原理
message在序列化成二进制后,是使用下图的key-value的形式。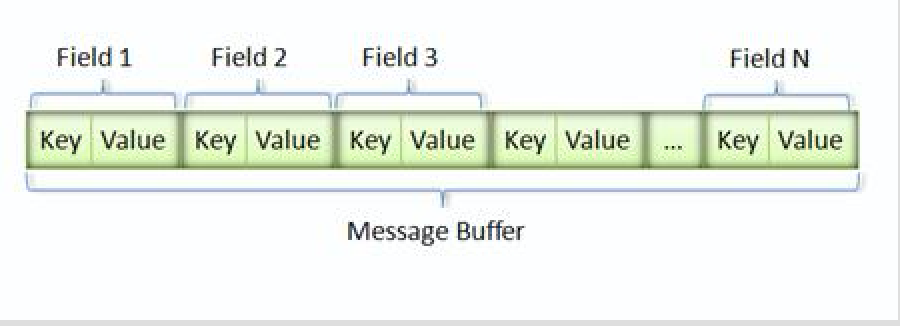
Key
Key的计算方式: (field_number << 3) | wire_type
wire_type参考下图: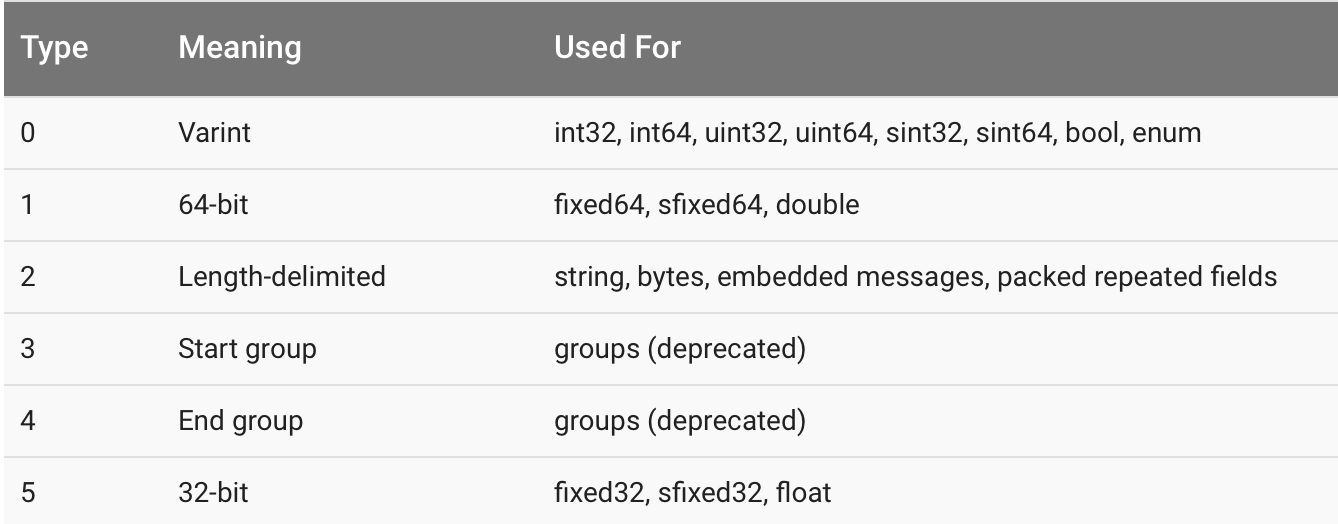
序列化过程
我们用string来举例:1
2
3message test {
string name = 2;
}
当name=testing的时候,最终序列化结果:12 07 74 65 73 74 69 6e 67
序列化过程:1
2
312: 2 << 3 | 2
07: 字符串长度
74 65 73 74 69 6e 67: testing
反序列化
我们用int来举例:1
2
3message test {
int32 id = 1;
}
当id=150的时候,序列化结果为:08 96 01
反序列化过程:1
2
3
4
5
608: 二进制为00001000,后三位表示wire_type,即为0,然后08右移3位表示filed number,即为1, 所以知道了后面的value是varint类型,并且是id的值。
96 01 = 1001 0110 0000 0001 (首位表示是否结束,1代表没结束,0代表结束)
→ 000 0001 ++ 001 0110 (varint使用little endian编码,丢到首位后,需要反转)
→ 10010110
→ 2 + 4 + 16 + 128 = 150 (得到了这个值为150)
优势与劣势
优势:
- 使用Protobuf的编译器,可以生成更容易在编程中使用的数据访问代码,可以使用同一个proto file生成多种语言的代码。
- 更好的兼容性,Protobuf设计的一个原则就是要能够很好的支持向下或向上兼容
- 简洁,体积小:消息大小只需要XML的1/10 ~ 1/3,速度快:解析速度比XML快20 ~ 100倍
劣势:
- 不适合数据大于1M的情况
- 可读性差,不适合与前端交互